Núcleo Português do
Museu da Pessoa
Data Extraction and Storage
After the construction and validation of the ontology, the next phase is to implement the Ingestion Module [M1]. In this approach the Ingestion Module [M1], will transform the input XML documents into RDF Triples. At an early stage, to realize the kind of information contained in the documents and how it would be represented, it was decided to conduct the analysis and extraction of information from documents manually. In other words, the three phases of Ingestion Module were accomplished by hand. To implement Museum of the Person it was decided to use a TripleStore to archive the ontology triples. Although there are other notations for ontology description, it was chosen RDF because we use CIDOC-CRM, FOAF and DBpedia that are described, in its original form, in RDF; moreover, RDF is completely suitable to accomplish all the project needs. Figure 1 shows an excerpt of the RDF Triples built.

The triple fragment shown in Figure 1 contains information about life story of Maria Cacheira. The first section (line 1-17) displays the biographic information about Maria Cacheira, as name (first, last name and full name), birth, sex, photo, profession, religion, and education. The second section (line 19-25) describes the birth event of Maria Cacheira, date and place of it. The last section (line 27-37) contains specific information about the photo of the interviewee, such as description, caption, file, date and place.
After building the RDF Triples manually, it was necessary to validate them to ensure that the very long textual description produced contained no errors. For this, it was used the W3C online tool RDF Validator, which checks the consistency of the RDF Triples and displays them in a table with three columns ‘subject’, ‘predicate’ and ‘object’.
The feedback obtained, after loading RDF file, was “VALIDATION RESULTS: Your RDF document validated successfully” that is just we want to get from that tool. The huge triples table was also useful for a quick visual reference.
After validated successfully by RDF Validator, the next step was to store them in a data set. For this it was used Apache Jena TDB, which is an RDF database.
After performing the three phases of the Ingestion Function [M1], it was understood how to make the extraction and analysis of semantic concepts and how to convert the triple ontology into RDF Triples. However, we came to the conclusion that it was a very team consuming work to be done manually for all documents in the repository, so it was decided to develop a text filter able to scan all files that compose an interview (BI, Edited Interview and Photograph Captions), extract relevant information and convert into a single RDF Triples file.
To develop the text filter, it was used the compilers generator system AnTLR (Another Tool for Language Recognition) integrated in AnTLRWorks tool, version 2.1, a plugin for NetBeans IDE.
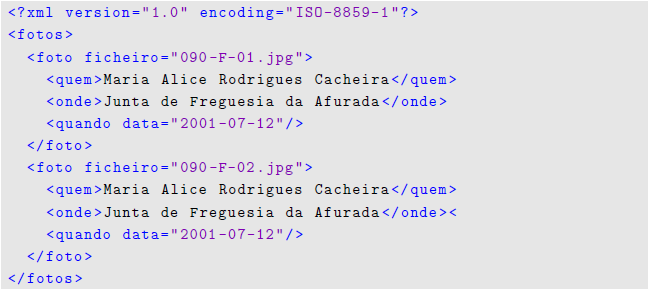
That text filter, or extractor, will accept an input document, like the one exemplified in Figure 2, and, after analyzing and processing it, will output a RDF description, like the one shown in Figure 3.

In Figure 4 it can be seen the three rules (namely, Cabec, Fotos e MP) corresponding to the three input files (BI, Photography Captions, and Edited Interview), respectively. When the extractor reads a XML tag defining the beginning of one of these three documents, it enters a special AnTLR mode to process that document’s content.
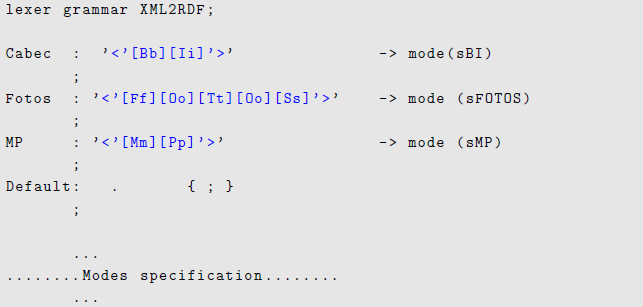
Figure 4 shows the main mode to process the Photography Caption XML documents. The Figure illustrates the general approach adopted: when a block opening tag is found, the appropriate mode is entered to consume the block contents; when the block closing tag is found, the processor exits the mode and returns to the initial mode.
The four auxiliary modes, called from the main one (see lines 13-19), contains the specific rules used to extract information from the four main blocks of the Photography Captions input document.

Figure 6 contains the rules (just a fragment is shown) executed at the end of the processing (mode activated at line 21 of Figure 5) to print out the RDF Triples built in the internal representation. This grammar fragment is actually responsible for the generation of the RDF output file.
