Núcleo Português do
Museu da Pessoa
Approach 2 - Relational Database
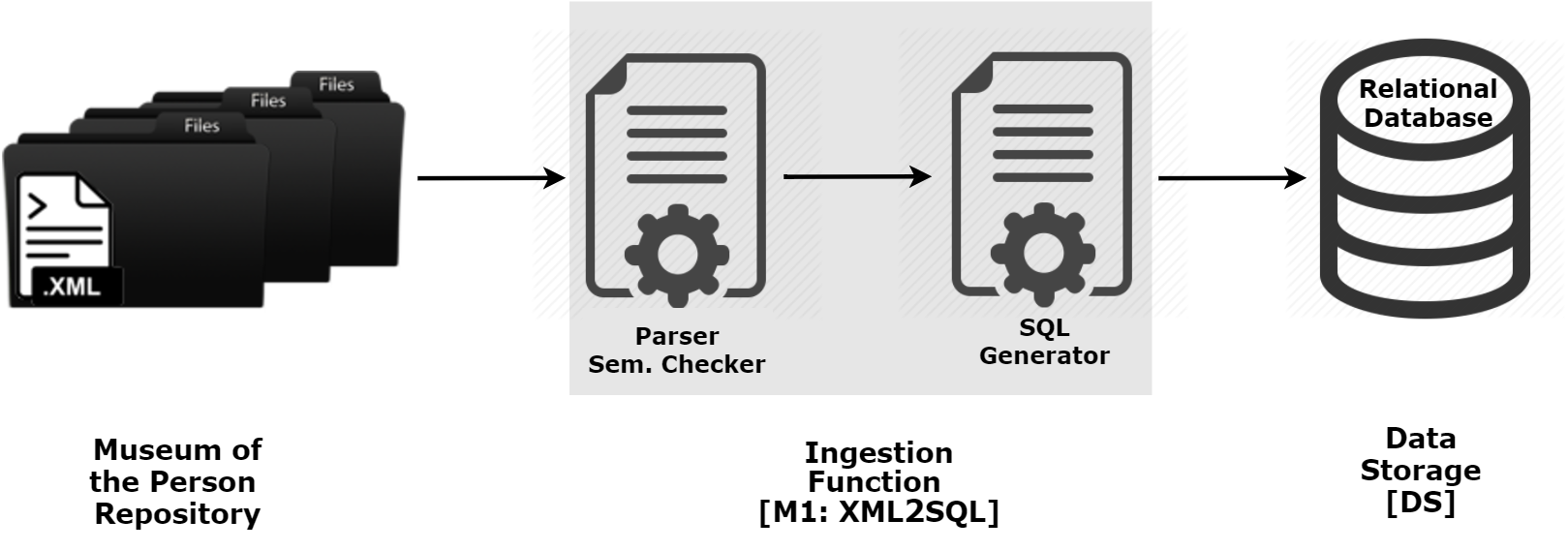
As in approach 1, the documents contained in the Repository of MP must be stored in a Data Storage [DS] but this time the choice is to resort to a traditional relational database; in this case the upload process into a database is different from the previous one, and so the Ingestion Function [M1] must be adapted. Now the input XML documents must be converted into SQL to populate the respective database. Figure 1 describes the first Module [M1] that in this case has two blocks:
- Parser and Semantic Checker that reads the repository documents and extracts the relevant data (annotated in XML), checking their semantic consistency;
- SQL Generator that generates automatically the SQL statements that insert the retrieved data into the database tables.
After the two phases of Ingestion Function [M1], the documents data populate the Relational Database schema, due to the SQL statements generated. As this schema is not directly related to the ontology, in this second approach an explicit mapping is necessary. This is the first task that must be implemented by the second Module [M2]. After making this mapping available, it is possible to resort to CaVa (Criação de Ambientes Virtuais de Aprendizagem) system to build automatically the Virtual Learning Spaces [VLS]. Notice that only the generator module of CaVa, CaVaGen, will be used in this context. Figure 2 sketches Module [M2] that in this case is composed of two parts:
- DB2Onto Mapping that associates concepts and relations belonging to the ontology with their respective instances stored in database (it allows to access database tables and fields to get the instances of the ontology concepts);
- CaVaGen that generates automatically the Virtual Learning Spaces from their formal specification based on the ontology.

In this second approach all the work concerned with the query generation according to the exhibition requirements and the answer processing to fulfill the rooms templates is left to CaVaGen. Obviously this strategy saves a lot of development effort. The only thing that is needed is the specification of the desired learning spaces in CaVaDSL.